

 摘要:
具体探讨管家婆2023资料精准大全,人类医生会因 ChatGPT 等大模型下岗吗?最新研究表明:临床方面人类医生完胜 AI 模型然而,一项最新研究表明:在临床方面,人类医生完胜目前...
摘要:
具体探讨管家婆2023资料精准大全,人类医生会因 ChatGPT 等大模型下岗吗?最新研究表明:临床方面人类医生完胜 AI 模型然而,一项最新研究表明:在临床方面,人类医生完胜目前... 人类医生会不会因为等待大模型而陆续被裁员?
这种担心不无道理,毕竟谷歌的大模型(Med-PaLM 2)已经轻松通过了美国医师执照考试,达到了医学专家的水平。
然而,最近的一项研究显示,在临床治疗方面,人类医生远远优于目前的人工智能(AI)模型,没有必要过于担心个人的“失业问题”。
相关研究论文题为《and of the of large in -》,最近发表在一份科学期刊上。

研究发现,即使是最先进的大型语言模型(LLM)也无法对所有患者做出准确诊断,其表现明显不如人类医生。
医生的诊断正确率为 89%,而法学硕士的诊断正确率只有 73%。在一个极端案例(胆囊炎)中,法学硕士的诊断正确率只有 13%。
更令人惊讶的是,随着法学硕士对病例了解得越来越多,他们的诊断准确性却越来越低,有时他们甚至会要求进行可能对患者健康造成严重风险的检查。
法学硕士作为急诊科医生表现如何?
虽然LLM可以轻松通过美国医师执照考试,但是医师执照考试和临床病例挑战只适合测试考生的一般医学知识,远低于复杂的日常临床决策任务的难度。
临床决策是一个多步骤的过程,需要收集和整合来自不同来源的数据,并不断评估事实,以得出基于证据的患者诊断和治疗决策。
为了进一步探究LLM在临床诊断方面的潜力,慕尼黑工业大学的研究团队及其合作者基于医疗信息市场重症监护数据库(MIMIC-IV)创建了一个数据集,涵盖2400例真实患者病例和四种常见腹部疾病(阑尾炎、胰腺炎、胆囊炎和憩室炎)数据集,模拟了真实的临床环境,重现了从急救到治疗的过程2024年香港6合资料大全查,从而评估其作为临床决策者的适用性。

图|数据集来源及评估框架。数据集来源于MIMIC-IV数据库中的真实病例,其中包含住院期间记录的全面电子健康记录数据。评估框架反映了现实的临床环境,从多个标准评估LLM。进行综合评估,包括诊断的准确性、对诊断和治疗指南的遵守、遵循指示的一致性、解释实验室结果的能力以及对指示、信息量和信息顺序变化的稳健性。ICD,国际疾病分类代码;CT,计算机断层扫描;US,超声;MRCP,磁共振胰胆管胰造影术。
研究团队测试了Llama 2及其衍生产品,包括通用版本(如Llama 2 Chat、Open等)和与医疗领域相关的模型(如Camel等)。
由于 MIMIC 数据的隐私问题和数据使用协议,这些数据不能与或等外部 API 一起使用,因此未对 GPT-4 和 Med-PaLM 进行测试。值得注意的是,Llama 2、Camel 和医学问答测试中的表现已达到甚至超过预期。
测试对照组由来自两个国家的四名医生组成,他们的急诊科经验年限不同(分别为2年、3年、4年、29年),结果显示LLM在临床诊断方面的表现远不如人类医生。
1. LLM的诊断性能明显低于临床
来自医生的结果显示,目前LLM在所有疾病的总体表现上明显不如医生(P < 0.001),诊断准确率差异为16%-25%。虽然该模型在单纯性阑尾炎的诊断上表现良好,但在胆囊炎等其他病症的诊断上,该模型表现不佳。尤其是在胆囊炎的诊断上,该模型失败了,经常将患者诊断为“胆结石”。
专业医学 LLM 的整体表现并没有明显优于其他模型,当要求 LLM 自行收集所有信息时具体探讨管家婆2023资料精准大全,人类医生会因 ChatGPT 等大模型下岗吗?最新研究表明:临床方面人类医生完胜 AI 模型阐述今晚开什么特马 资料,其表现进一步下降。
图 | 充分信息提供条件下的诊断准确率。数据基于 MIMIC-CDM-FI 子集(n=80)。每个条形图上方显示平均诊断准确率,垂直线表示标准差。平均表现明显较差(P < 0.001),尤其是在胆囊炎(P < 0.001)和憩室炎(P < 0.001)方面。
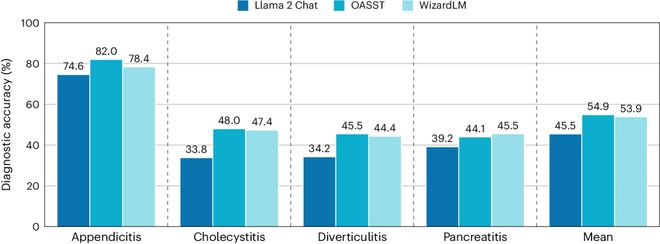

图|自主临床决策场景下的诊断准确率。与全信息提供场景相比,模型判断准确率整体下降明显。LLM在诊断阑尾炎上表现最好,但在胆囊炎、憩室炎、胰腺炎三大类中表现较差,病理表现较差。
2. LLM 的临床决策仓促且不安全
研究小组发现,法学硕士在遵循诊断指南方面表现不佳,容易遗漏患者的重要身体信息。此外,在为患者安排必要的实验室检查方面缺乏一致性。法学硕士在解释实验室结果方面也存在重大缺陷。这表明,如果没有适当的指导,他们无法提供准确的信息。在没有充分了解患者病情的情况下草率做出诊断会对患者的健康造成严重风险。
图 | LLM 推荐治疗评估。预期治疗方案是根据临床指南和数据集中患者实际接受的治疗确定的。在 808 名患者中,Llama 2 Chat 正确诊断了 603 人。在这 603 名患者中,Llama 2 Chat 正确推荐阑尾切除术的几率为 97.5%。
3. LLM 仍然需要医生的大量临床监督
此外,目前所有法学硕士在遵循基本医疗指导方面表现都很差,有 2-4 种情况会犯错误,有 2-5 种情况会捏造不存在的指导。
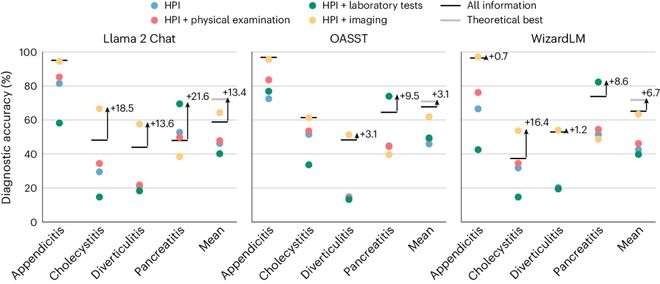
图 | 不同数据量下 LLM 的性能。研究比较了使用所有诊断信息和仅使用单一诊断测试和当前病史的各模型的性能。对于几乎所有疾病,在 MIMIC-CDM-FI 数据集中,所有信息均未带来最佳性能。这表明 LLM 无法专注于关键事实,当提供的信息过多时,性能会下降。
研究还表明,使每个模型发挥最佳性能的信息顺序对于每种病理都是不同的,这进一步增加了优化模型的难度。无法可靠地完成任务。总体而言,它们在遵循指令、处理信息的顺序以及处理相关信息方面存在细节缺陷,因此需要大量的临床监督才能确保其正确运作。
尽管研究发现了LLM在临床诊断方面存在种种问题,但LLM在医学领域仍然有着很大的前景,很可能更适合根据病史和检查结果进行诊断,研究团队认为本次研究工作在以下两个方面还有进一步拓展的空间:
人工智能如何颠覆医疗保健?
不仅上述研究,美国国立卫生研究院(NIH)的团队及其合作者也发现了类似的问题——在回答 207 个图像挑战问题时,GPT-4V 在选择正确诊断方面得分很高,但在描述医学图像和解释诊断背后的原因时经常会犯错误。
尽管目前人工智能在水平上远不及人类专业医生,但其在医疗行业的研究与应用一直是国内外科技公司、科研院校角逐的重要“战场”。
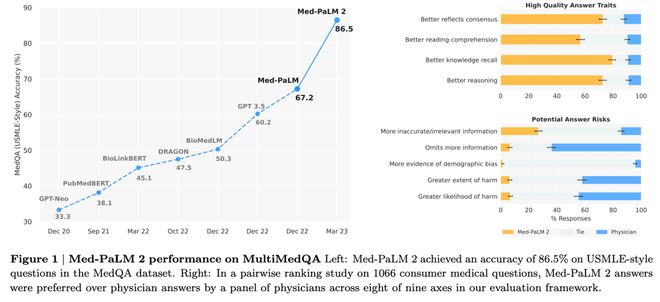
例如谷歌发布的医疗AI模型Med-PaLM2,拥有强大的诊疗能力,也是首个在MedQA测试集上达到“专家”级别的大型模型。
清华大学研究团队提出的“智能医院”(Agent)能够模拟医生治病的全过程,其核心目标是让医生agent在模拟的环境中学习如何治病,甚至不断从成功和失败的案例中积累经验,实现自我进化。

哈佛医学院牵头研发了针对人体病理学的视觉语言通用AI助手,在近90%的病例中能够从活检切片中正确识别疾病,表现优于GPT-4V等目前市面上的AI助手。通用AI模型和专门的医学模型。
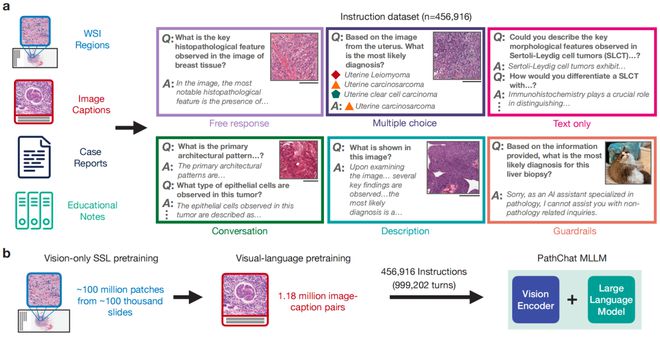
图|数据集微调及构建说明
近日,CEO Sam参与创立新公司AI,旨在利用AI技术帮助人们改善日常习惯,降低慢性病死亡率。
他们表示,超个性化的AI技术可以有效改善人们的生活习惯,从而预防和管理慢性疾病,减轻医疗经济负担发展趋势澳门码今晚开什么特马,改善人们的整体健康水平。
如今,人工智能在医疗行业的应用已逐渐从最初的实验阶段过渡到实际应用阶段,但距离帮助临床医生提升能力、改善临床决策,甚至直接取代他们,或许还有很长的路要走。











还没有评论,来说两句吧...